Hyperparameter tuning¶
Hyperparameter tuning is a key part of training machine learning models. For use-cases ranging from grid-search
to gaussian processes, burr is a simple way to implement robust, failure-resistant hyperparameter optimization. This involves keeping
track of hyperparameters and metrics and feeding these into a decision function to determine where to look next.
burr’s state machine can help you write and manage that process.
This is a WIP! Please see the placeholder/example sketch in the repository and contribute back if you have ideas via associated issue here.
High-level view¶
A machine learning training system can easily be modeled as a state machine.
While often, this is more of a DAG (E.G. query_data -> feature_engineer -> train_model -> evaluate_model), there
are some interesting reasons this as a state machine.
More granular training routines¶
If, rather than treating train as a action, you treat train_epoch as an action, you can utilize the abstractions
burr represents to get the following benefits:
Checkpointing¶
You can store the current params + best model (or pointers to them). Then go back to the failure point. This allows you to recover from failure in a generic way.
Decoupling training logic from termination condition¶
You can have a condition that checks training completeness based on metric history, which is different from the training logic itself. This allows you to easily swap in and out termination conditions (testing them against each other or running different ones in different scenarios), as well as easy reuse.
Visibility into lower-level training¶
Similar to hooks in pytorch lightning, you can use Burr hooks to log metrics, visualize, etc… at each step. This allows you to have a more granular view of training that updates live (obviuosly depending on the UI/model-monitoring you’re using.)
Human in the loop¶
While some models are trained in a single-shot and shipped to production, many require human input. Burr can be used to express training, then checkpoint/pause the state while a human is evaluating it, and have their input (e.g. go/no-go) passed in as an input parameter.
Note that this still requires a scheduling tool (say a task executor that runs until the next human input is needed), but that task executor does not need to be complicated (all it needs to do is run a job when prompted, and possibly on a chron schedule).
Hyperparameter training¶
Similar to epoch training, hyperparameter training can be modeled as a state machine. The system makes a decision about what to look for next based on the prior results. Furthermore, one can model a step that handles multiple jobs, keeping them alive/ launching new ones as they complete (based on state).
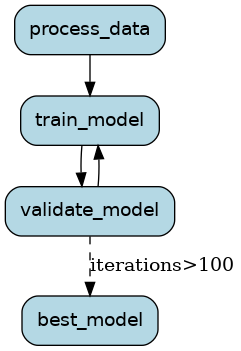 .
.
Code example¶
This uses the class-based API for defining an action.
"""
This is a sketch of an example of a machine learning training pipeline using Burr where you
want to do something dynamic like train a model for a variable number of iterations and then
pick the best model from each of the iterations based on some validation metric. E.g. hyperparameter search.
You could adjust this example to continue training a model until you reach a certain validation metric,
or hit a max number of iterations (or epochs), etc.
Note: this example uses the class based API to define the actions. You could also use the function+decorator API.
"""
import burr.core.application
from burr.core import Action, Condition, State, default
class ProcessDataAction(Action):
@property
def reads(self) -> list[str]:
return ["data_path"]
def run(self, state: State, **run_kwargs) -> dict:
"""This is where you would load and process your data.
You can take in state and reference object fields.
You need to return a dictionary of the results that `update()` will then use to update the state.
"""
# load data, and run some feature engineering -- create the data sets
# TODO: fill in
return {"training_data": "SOME_OBJECT/PATH", "evaluation_data": "SOME_OBJECT/PATH"}
@property
def writes(self) -> list[str]:
return ["training_data", "evaluation_data"]
def update(self, result: dict, state: State) -> State:
return state.update(
training_data=result["training_data"], evaluation_data=result["evaluation_data"]
)
class TrainModel(Action):
@property
def reads(self) -> list[str]:
return ["training_data", "iterations"]
def run(self, state: State, **run_kwargs) -> dict:
"""This is where you'd build the model and on each iteration do something different.
E.g. hyperparameter search.
"""
# train the model, i.e. run one "iteration" whatever that means for you.
# TODO: fill in
return {
"model": "SOME_MODEL",
"iterations": state["iterations"] + 1,
"metrics": "SOME_METRICS",
}
@property
def writes(self) -> list[str]:
return ["models", "training_metrics", "iterations"]
def update(self, result: dict, state: State) -> State:
return state.update(
iterations=result["iterations"], # set current iteration value
).append(
models=result["model"], # append -- note this can get big if your model is big
# so you'll want to overwrite but store the conditions, or log somewhere
metrics=result["metrics"], # append the metrics
)
class ValidateModel(Action):
@property
def reads(self) -> list[str]:
return ["models", "evaluation_data"]
def run(self, state: State, **run_kwargs) -> dict:
"""Compute validation metrics using the model and evaluation data."""
# TODO: fill in
return {"validation_metrics": "SOME_METRICS"}
@property
def writes(self) -> list[str]:
return ["validation_metrics"]
def update(self, result: dict, state: State) -> State:
return state.append(validation_metrics=result["validation_metrics"])
class BestModel(Action):
@property
def reads(self) -> list[str]:
return ["validation_metrics", "models"]
def run(self, state: State, **run_kwargs) -> dict:
"""Select the best model based on the validation metrics."""
# TODO: fill in
return {"best_model": "SOME_MODEL"}
@property
def writes(self) -> list[str]:
return ["best_model"]
def update(self, result: dict, state: State) -> State:
return state.update(best_model=result["best_model"])
def application(iterations: int) -> burr.core.application.Application:
return (
burr.core.ApplicationBuilder()
.with_state(
data_path="data.csv",
iterations=10,
training_data=None,
evaluation_data=None,
models=[],
training_metrics=[],
validation_metrics=[],
best_model=None,
)
.with_actions(
process_data=ProcessDataAction(),
train_model=TrainModel(),
validate_model=ValidateModel(),
best_model=BestModel(),
)
.with_transitions(
("process_data", "train_model", default),
("train_model", "validate_model", default),
("validate_model", "best_model", Condition.expr(f"iterations>{iterations}")),
("validate_model", "train_model", default),
)
.with_entrypoint("process_data")
.build()
)
if __name__ == "__main__":
app = application(100) # doing good data science is up to you...
app.visualize(output_file_path="statemachine", include_conditions=True, view=True, format="png")
# you could run things like this:
# last_action, result, state = app.run(halt_after=["best_model"])