Recursive Applications¶
Burr supports sub-applications. E.G. running Burr within Burr. Currently this capability is only done with tracking (linking applications), but we are actively working on building first-level constructs that allow this.
This can enable the following use-cases (among many others):
Parallel results to different LLMs for comparison
Multiple simultaneous tasks/chains for an LLM to answer at once
Black-boxing an action as a subset of tasks
Running multiple queries simultaneously and getting an LLM to synthesize
And so on. These can be arbitrarily complex and nested, allowing agents consisting of agents consisting of agents…

You can find an example here.
Tracking¶
Currently, to leverage nested Burr apps, you do the following:
Create a parent app (as you normally would)
Leverage tracking
Create an action inside that
Run your Burr sub-application inside that action
Wire through tracker + parent data for the sub-application
After creating a simple application (1)/(2) above, you can wire through the tracker like this (some pseudocode, see the example for a fully working application).
@action(reads=["parameters_to_map"], writes=["joined_results"])
def run_multiple_sub_apps(state: State, __context: ApplicationContext) -> State:
# for every parameter incoming, run a sub-application
results = []
for parameter_set in state["parameters_to_map"]:
subapp = (
ApplicationBuilder()
.with_actions(...)
.with_transitions(...)
.with_tracker(__context.tracker.copy())
.with_spawning_parent(
__context.app_id,
__context.sequence_id,
__context.partition_key,
)
.with_entrypoint(...)
.with_state(...)
.build()
)
results.append(subapp.run(...))
joined = _join(results)
return state.update(joined_results= _join(results))
Note we’re simply passing through the tracker to the next app, which sets a link between them. The tracker knows how to record the link so its in the UI.
You can also run this in parallel – this leverages joblib’s Parallel and delayed functions, but you can use whatever tooling you want (multiprocessing, threading, etc…).
@action(reads=["parameters_to_map"], writes=["joined_results"])
def run_multiple_sub_apps(state: State, __context: ApplicationContext) -> State:
def run_subapp(parameter_set):
subapp = (
ApplicationBuilder()
.with_actions(...)
.with_transitions(...)
.with_tracker(__context.tracker.copy() if __context.tracker is not None else None)
.with_spawning_parent(
__context.app_id,
__context.sequence_id,
__context.partition_key,
)
.with_entrypoint(...)
.with_state(...)
.build()
)
return subapp.run(...)
results = Parallel(n_jobs=-1)(delayed(run_subapp)(parameter_set) for parameter_set in state["parameters_to_map"])
joined = _join(results)
return state.update(joined_results=joined)
Note the following:
You don’t have to pass in partition_key, but you need to pass in the app_id and sequence_id so the app can track
You currently need to run
__context.tracker.copy()to ensure the tracker is passed through correctly. We will likely be relaxing this, but it could corrupt the tracking state if you forget.You may want to have more control over the application ID’s – you may want to use a stable hash of the parameters and the parent App ID
For persistence, you’ll want to use (3) to ensure a stable hash – have the sub-application load its own state from the ID, resuming where it left off.
We currently don’t wire through persisters, although we are planning to add that shortly. For the meanwhile, you’ll want to leverage the right persister yourself.
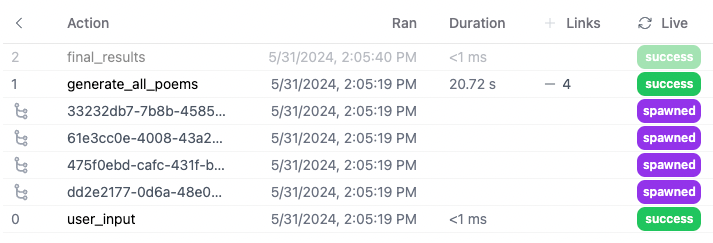
When you track in the UI, you will see the following (in this example we’re generating poems of different styles in parallel):
Alternatives¶
If, for some reason, you want to run a Burr application inside a burr application but can’t effectively wire through the tracker/context (say, for instance, that it’s run through levels of other frameworks), you can get access to the active context and tracker by using the following:
from burr import get_active_context, get_active_tracker, ApplicationContext
@action(reads=["parameters_to_map"], writes=["joined_results"])
def my_action(state: State) -> State:
context = ApplicationContext.get()
def run_subapp(parameter_set):
subapp = (
ApplicationBuilder()
.with_actions(...)
.with_transitions(...)
.with_tracker(context.tracker.copy() if context.tracker is not None else None)
.with_spawning_parent(
context.app_id,
context.sequence_id,
context.partition_key,
)
.with_entrypoint(...)
.with_state(...)
.build()
)
return subapp.run(...)
results = Parallel(n_jobs=-1)(delayed(run_subapp)(parameter_set) for parameter_set in state["parameters_to_map"])
joined = _join(results)
# do something with the context and tracker
return state
Future Improvements¶
We are working on the following:
A first class way to define a recursive application application to allow for more ergonomic management of the above
Static visualization of the recursive application when using (1)
A more ergonomic way to pass through the tracker
Stay tuned!